

Avoir à sa disposition à la demande et sans limite: des capacités de calcul, des données et des applications; c'est la promesse du cloud computing. Du coup on a parfois l'impression que le cloud est une solution miracle et qu'une fois qu'on a mis son application ou ses données dans le cloud, on peut "dormir tranquille".
Mais quels engagements prend le fournisseur de cloud que vous avez choisi ? Combien de temps mettra t-il pour redémarrer votre solution en cas de problème ? Peut-il perdre vos données ? Voilà des questions classiques que l'on me pose régulièrement lorsque je parle de cloud computing et auxquelles je vais essayer de répondre ici en explorant les contrats de différents fournisseurs.
Engagements ?
Lorsqu'un informaticien propose une solution informatique à un utilisateur, la première chose qu'il défini ce sont les engagements qu'il prend. Ces engagements lui permettent de répondre à des interrogations simples (et légitimes !) de l'utilisateur, notamment:
Ces "engagements" que prennent les Directions Informatiques auprès de leurs utilisateurs métiers s'appellent habituellement "SLA" (Service Level Agreement) ou en français "Contrat de service". Evidemment, plus la SLA est contraignante, plus le prix de la solution proposée par l'informatique est élevée.

Comme des hébergeurs traditionnels, les fournisseurs de solutions Cloud s'engagent sur des SLA. Pour bien comprendre sur quoi ils s'engagent (et sur quoi ils ne s'engagent pas), je vous propose de faire une lecture croisée du SLA des solutions cloud : Amazon, Azure, Google App Engine, Google Apps et BPOS. Mon objectif n'étant pas d'être exhaustif, je m'intéresserais plus spécifiquement à 4 axes:
Disponibilité: "99,95%"
La disponibilité des solutions de Cloud est assez uniforme entre les différents acteurs: le chiffre à retenir est : 99,95% de disponibilité. C'est un niveau de service très élevé; à titre indicatif si on le rapporte aux nombres de minutes dans 1 année cela signifie à peine 3 minutes 4 heures d'indisponibilité par an. Mais, on va le voir, ce n'est pas aussi simple que cela car le mode de calcul est assez différent d'un fournisseur à l'autre.

Amazon propose un niveau de disponibilité de 99,95%, le mode de calcul du temps de disponibilité est décrit dans le texte qui suit:
Le “Pourcentage de Temps Utilisable Annuel” est calculé en soustrayant de 100% le pourcentage de périodes de 5 minutespendant L’Année de Service durant laquelle Amazon EC2 était en statut de “Région Indisponible.” Si vous avez utilisé Amazon EC2 pendant moins de 365 jours, votre Année de Service est toujours constituée des 365 jours précédents mais toujours avant le début de votre utilisation du service sera estimé comme ayant 100% de Disponibilité de Région.
Autrement dit, pour Amazon, le calcul se base sur des périodes de 5 minutes (ce qui est plus facile à respecter que par période d'une minute) et surtout il s'appuie sur le statut de la "Région", c’est-à-dire l'indisponibilité de tout le Datacenter. Ainsi en théorie s'il n'y a que votre machine virtuelle indisponible dans le Datacenter pendant plusieurs semaines, cela n'empêche pas Amazon de respecter son engagement ! De plus si vous utilisez une instance pour une durée inférieure à un an, la plateforme est considérée comme ayant été disponible tout le reste du temps ce qui a forcément un effet d'écrasement sur le taux global.

Pour Azure, le niveau de disponibilité est également de 99,95%, voilà le texte qui détaille le calcul:
For compute, we guarantee that when you deploy two or more role instances in different fault and upgrade domains your Internet facing roles will have external connectivity at least 99.95% of the time.
Ici la seule restriction importante dans l'engagement et qu'il n'est valable qu'à partir du moment où vous achetez deux instances qui se répliquent mutuellement. Dans la console d'administration Azure, il y a d'ailleurs une message d'avertissement qui le rappelle lorsque vous n'avez qu'une seule instance.


Pour rester dans les solutions PaaS, Google App Engine propose également une disponibilité à 99,95%. Bizarrement néanmoins le document est encore en draft ce qui est peu réconfortant pour les clients (on n'a pas l'impression que c'est réellement un engagement...). Le texte décrit les engagements comme suit:
During the term of the applicable Google App Engine Agreement, Google will make commercially reasonable efforts to keep the Google App Engine service (the "Service") operational and available to Customer at least 99.95% of the time in a monthly billing cycle(the "Google App Engine SLA" or "SLA").
On notera les précautions de formulation sur les engagements (nous y reviendrons plus loin). On notera aussi qu'ici le calcul est indiqué par périodes mensuelles glissantes.

Google Apps, la solution SaaS de messagerie et collaboration de Google propose une disponibilité de 99,9% (ce qui est moins bon que 99,95% :-). Le texte la décrit comme suit:
Pendant la durée du Contrat Google Apps applicable (le "Contrat"), l'interface Web des Services Google Apps couverts sera opérationnelle et accessible au Client au moins 99,9 % du temps au cours d'un mois calendaire quel qu'il soit (…). (…) "Pourcentage de disponibilité mensuelle" désigne, pour un mois calendaire donné, le nombre total de minutes de ce mois moins la durée (exprimée en minutes) des Interruptions, divisé par le nombre total de minutes du mois.
L'engagement est assez proche de celui de Google App Engine, le temps étant calculé sur un nombre de minutes par mois.

BPOS, la solution de messagerie SaaS de Microsoft propose elle aussi un niveau de disponibilité de 99,9%. Le calcul décrit dans le texte ci-dessous, est un peu différent et moins restrictif pour Microsoft:
"Temps d'Indisponibilité" désigne le nombre total de minutes dans un mois où les aspects d'un Service indiqué (…) ne sont pas disponibles, multiplié par le nombre d'utilisateurs concernés, à l'exception du Temps d'Indisponibilité Planifié (…)
En effet, le temps d'indisponibilité est dépendant du nombre d'utilisateurs ce qui peut diluer les problèmes d'indisponibilité d'un utilisateur particulier. Par ailleurs, il est fait mention d'un temps d'indisponibilité planifié qui est défini comme suit:
"Temps d'Indisponibilité Planifié" désigne les périodes de Temps d'Indisponibilité que nous publions ou notifions au moins cinq jours avant le début dudit Temps d'Indisponibilité, ou une opération de maintenance ou de mise à jour planifiée du réseau, du matériel ou du Service, et ledit Temps d'Indisponibilité ne dépasse pas dix heures par année calendaire.
En toute logique, cette indisponibilité planifiée devrait se déduire de l'indisponibilité réelle ce qui n'est pas le cas (à noter que jusqu'au mois de janvier 2011, Google intégrait également l'indisponibilité planifiée dans son calcul).
Pérennité des données: "on fait notre possible"
Au-delà de la disponibilité, on attend d'une solution de cloud qu'elle garantisse la pérennité des données afin d'être sûr de ne rien perdre. Si évidemment toutes les plateformes mettent en avant la pérennité comme point fort, cela ne se traduit pas clairement par des engagements dans la SLA.
Pour Amazon, le stockage se fait via des volumes de données EBS. Voici le texte décrivant le service proposé:
Les volumes Amazon EBS sont conçus pour être hautement disponibles et fiables. Les données du volume Amazon EBS sont répliquées sur plusieurs serveurs dans une zone de disponibilité, afin de prévenir la perte des données due à une défaillance d’un seul composant. (…). A titre d’exemple, les volumes qui fonctionnent avec 20 Go ou moins de données modifiées depuis l’instantané Amazon EBS le plus récent peuvent s’attendre à un taux de défaillance annuel (AFR) compris entre 0,1% – 0,5%, lorsque la défaillance se réfère à une perte complète du volume. Cela se compare à des disques durs qui échoueront généralement avec une AFR de l’ordre de 4%, rendant les volumes EBS 10 fois plus fiables que les lecteurs de disques typiques de base.
Parce que les serveurs Amazon EBS sont répliqués au sein d’une seule zone de disponibilité, répliquer en miroir les données à travers plusieurs volumes Amazon EBS dans la même zone de disponibilité n’améliorera pas de façon significative la durabilité du volume. Toutefois, pour ceux qui veulent encore plus de durabilité, Amazon EBS offre la possibilité de créer des instantanés cohérents de vos volumes, à un moment donné, qui sont ensuite stockés sur Amazon S3, et automatiquement répliqués à travers plusieurs zones de disponibilité. (…). Dans le cas peu probable que votre volume Amazon EBS tombe en panne, tous les clichés de ce volume restera intact, ce qui vous permettra de recréer le volume du dernier point d’instantané.
En fait, il ne s'agit pas réellement d'un engagement mais plutôt d'une description des efforts réalisés par Amazon pour limiter la défaillance de vos donnés. On notera qu'il est précisé qu'il appartient à l'utilisateur de créer des "instantanés" de ses volumes EBS dans Amazon S3 s'il veut se prémunir d'une défaillance d'une zone de disponibilité (crash d'un datacenter complet). Néanmoins, le texte de la SLA d'Amazon S3 ne donne pas plus de précision sur les engagements d'Amazon en terme de pérennité.
Dans Azure, les données sont stockées soit dans un stockage adapté au cloud (hiérarchique), soit dans une base de données relationnelle SQL Azure.
Pour le stockage adapté, le texte de la SLA fait uniquement mention d'échecs de transaction de stockage et détaille les engagements de délai d'exécution:

Pour SQL Azure, le texte du SLA défini l'indisponibilité des opérations de lecture/écriture mais ne mentionne pas d'engagement.
Un intervalle de 5 minutes est marqué comme indisponible si toutes les tentatives mises en œuvre par le client pour établir une connexion au service SQL Azure se sont soldées par un échec ou ont mis plus de 30 secondes pour aboutir, ou si toutes les opérations de lecture/écriture de base (telles que décrites dans notre documentation technique) échouent une fois la connexion établie.
Pour Google Apps, rien n'est mentionné spécifiquement dans la SLA sur la pérennité des données. Par contre, là aussi c'est un élément fort mis en avant dans le texte décrivant le service:
Chaque donnée est répliquée dans plusieurs centres de données, de sorte à dupliquer le contenu de la messagerie vers un centre de données principal et un centre de données de sauvegarde, le tout en temps réel. Des contrôles réguliers et des audits SAS 70 sont également effectués par des sociétés indépendantes.
A noter la référence à la norme SAS 70 qui est une procédure américaine d'audit "s’appliquant aux entreprises qui offrent des prestations susceptibles d’affecter la situation financière de leurs client" (Wikipédia).
BPOS ne mentionne pas non plus dans le texte de sa SLA d'éléments détaillés sur la pérennité des données. Par contre, dans le texte de description du service il est également fait référence explicitement à l'implication de Microsoft pour garantir la pérennité et la sécurité des données.
The Standard version of the Business Productivity Online Standard Suite will be seeking a SAS 70 Type II audit attesting to the effectiveness of Microsoft internal controls. Although our U.S. datacenters maintain a SAS 70 Type II for the physical controls of each facility, the Services (Live Meeting, Exchange Hosted Services, Exchange Online, SharePoint Online and Office Communications Online) themselves do not.
Périmètre de responsabilité: "est-ce que c'est de ma faute ?"
Si un fournisseur de cloud ne tient pas ses engagements, est-il nécessairement responsable ? Là-dessus, même si le libellé diffère légèrement, on retrouve une réponse commune (et habituelle dans des contrats de services): on ne peut pas demander l'impossible à un fournisseur. Si vous perdez vos données pour une raison qui n'est pas de sa responsabilité directe (tremblement de terre, tsunami, chute d'appareil aérien sur le datacenter, …), ce n'est pas de sa faute (et c'est tant pis pour vous ![]() ).
).
Amazon détaille explicitement l'exclusion de son périmètre de responsabilité dans le texte de sa SLA:
L’Engagement de Service ne s’applique pas à toute indisponibilité, suspension ou résiliation de Amazon S2, ou tout autre problème de performance de Amazon S2 (...) causé par des facteurs échappant raisonnablement à notre contrôle, dont les cas de force majeure, les problèmes d’accès à internet ou les problèmes en rapport au delà du point de démarcation de Amazon S2, (…)
On retrouve des termes très similaires dans le contrat Google avec quelques exemples:
Aucune partie ne pourra être tenue pour responsable d'une exécution inappropriée du Contrat dans la mesure où elle est causée par une situation (par exemple, catastrophe naturelle, acte de guerre ou de terrorisme, émeute, conditions de travail, action gouvernementale et dysfonctionnements liés à Internet) échappant au contrôle raisonnable de la partie.
Azure et BPOS disposent également de ce type de clause dans le texte de leur SLA :
Le présent SLA ainsi que tous les Niveaux de service applicables ne s'appliquent pas en cas de problèmes de performances ou de disponibilité (…) liés à des facteurs hors du contrôle raisonnable de Microsoft (…)
Dédommagement : "je te fais un Avoir"
Supposons que le fournisseur de cloud n'ait pas tenu ses engagements et que sa responsabilité soit clairement engagée, quel dédommagement pouvez-vous attendre ? Sur ce point, les fournisseurs de cloud proposent tous la même chose: un Avoir sur l'utilisation de leur service, plafonné sur au montant de ce que vous avez déjà acheté. Autrement dit, quelque soit la valeur réelle de vos données, le fournisseur n'est engagé que sur la somme que vous lui avez versé. Et si vous n'êtes pas content de son service, il vous propose... de continuer.
Chez Amazon cet Avoir est appelée "Crédit de Service" et est de 10% de la facture:
Au cas ou Amazon EC2 ne respecte pas ses engagements de Pourcentage de Temps Utilisable Annuel, vous pourrez recevoir un Crédit de Service (…) Si le Pourcentage de Temps Utilisable Annuel pour un client tombe en dessous de 99,95% pour l’Année de Service, ce client remplit les conditions pour recevoir un Crédit de Service égal à 10% de sa facture (…) pour la Période de Crédit Eligible.
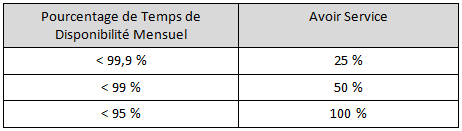
Pour Azure, on parle d' "Avoir service" dont le montant est compris entre 10 et 25% de la facture selon la dégradation du niveau de service:

Pour Google Apps Engine, l'Avoir s'appelle "Crédit de service". Sa valeur est comprise entre 10% et 100% du montant payé mensuellement:
Service Credits:
< 99.95% - ≥ 99.00% = 10% of applicable Monthly Billing Cycle Charge
< 99.00% - ≥ 95.00% = 25% of applicable Monthly Billing Cycle Charge
< 95.00% - ≥ 90.00% = 50% of applicable Monthly Billing Cycle Charge
< 90.00% = 100% of applicable Monthly Billing Cycle Charge
[Mise à jour novembre 2011]
Dans ses conditions définitives annoncées ce mois-ci, le crédit de service de Google s'arrête désormais à 50% pour 95% d'indisponibilité. On peut imaginer que Google considère la plate-forme désormais suffisament stable pour ne plus pouvoir descendre en dessous de 95% d'indisponibilité.
Pour Google Apps, Google précise explicitement dans son contrat, le niveau de dédommagement que l'on peut attendre:
AUCUNE PARTIE NE POURRA ÊTRE TENUE POUR RESPONSABLE, DANS LE CADRE DU PRÉSENT CONTRAT, POUR UN MONTANT SUPÉRIEUR À CELUI PAYÉ PAR LE CLIENT À GOOGLE AU COURS DES DOUZE MOIS PRÉCÉDANT L'ÉVÉNEMENT QUI A ENGAGÉ CETTE RESPONSABILITÉ.
L'Avoir s'appelle ici aussi "Crédit de Service" et correspond à un nombre de jours offerts pouvant globalement monter jusqu'à 50% du coût mensuel:

Pour BPOS, comme pour Azure, on parle également d'"Avoir service", l'engagement est néanmoins plus fort car il peut aller jusqu'à 100% de la somme versée:
Conclusion
En synthèse on se rend donc compte que les fournisseurs de cloud:
Faut-il être inquiet de ce constat ? Non. D'une part parce que les engagements sont déjà très forts et d'autres part parce qu'au-delà des engagements contractuels, dans un marché hautement concurrentiel aucun fournisseur de cloud ne peut aujourd'hui laisser supposer qu'il n'est pas fiable. Il n'y a qu'à voir comment la presse se fait l'écho de la moindre défaillance, qu'elle soit chez Amazon, Google ou Microsoft pour comprendre que chaque fournisseur fera un effort considérable pour corriger le moindre problème.
Pourtant, il faut être réaliste, la défaillance d'un fournisseur de cloud est possible et elle a toute les chances d'arriver pour un client donné à un moment donné. L'erreur serait simplement de ne pas l'avoir anticipée et d'avoir fait confiance aveuglément en son fournisseur de cloud sous prétexte qu'il a une infrastructure redondante/sécurisée/haute performance.
Récemment, un datacenter complet d'Amazon a souffert d'une panne qui a rendu indisponible toute une région. Malgré tous les efforts d'Amazon il semble que quelques clients ont perdu des données bien qu'Amazon ait assuré avoir respecter son SLA. Qui est responsable ? Comme l'explique mon article: ce sont les clients eux-mêmes ! Le cloud n'est qu'un outil, c'est de la responsabilité des informaticiens qui choisissent une plate-forme de cloud de construire le SLA qui va avec et d'engager les ressources nécessaires pour le respecter. Non, le cloud ce n'est pas magique.
[Mise à jour août 2011]
L'actualité me donne l'occasion de mettre à jour ce billet pour l'illustrer plus concrètement . En effet, suite à un orage à Dublin, ce sont les datacenters de Microsoft et d'Amazon qui sont tombés pour cause de panne électrique. Il se trouve que nous hébergeons des clients chez l'un et chez l'autre ce qui me permet de décrire quel a été l'impact pour eux et quelle a été la communication du fournisseur.
Chez Microsoft, le problème a provoqué une indisponibilité de BPOS, la solution de messagerie SaaS pendant plusieurs heures. Voici la communication que nous avons reçu suite à l'incident:
Cher client,
Microsoft Online Services s’efforce de fournir un service d’excellence à tous ses clients. Néanmoins, le 7 août dernier, les clients reliés au « data center » de Dublin n’ont pu accéder à ces services y compris à la suite « Business Productivity Online Standard » (BPOS). Nous vous présentons nos excuses pour les désagréments occasionnés à vous-même et vos employés.
Nous nous devons de communiquer avec nos clients de façon transparente et honnête sur les dysfonctionnements de nos services et les actions correctives mises en place pour éviter que cela ne se reproduise.
• Que s’est-il passé ?
o Notre première analyse indique une coupure de courant générale à Dublin qui a causé des problèmes d’accès au « data center BPOS ».
o Normalement, nos générateurs de secours auraient dû prendre en charge la défaillance mais la coupure de courant était tellement importante qu’elle a également touché une partie de nos générateurs de secours.
o Afin de remettre le courant, nous avons dû synchroniser manuellement les générateurs de secours, ce qui a entrainé un retard dans la reprise du service.
o Le « Rapport de service » (Service health dashboard) a été mis à jour régulièrement pendant ces événements pour tenir informé nos clients.
• Quelles actions ont été prises en regard de cette panne ?
o Le service BPOS est opérationnel avec nos générateurs principaux qui sont des installations à haute disponibilité.
o Nous continuons de surveiller l’état général du courant électrique très régulièrement afin de maintenir le niveau maximum de service auprès de nos clients.
Nous sommes conscients que toute interruption du service peut avoir un impact sur votre activité. Afin de refléter notre engagement à assurer une prestation de la plus haute qualité, Microsoft s’engage à fournir pro-activement un remboursement égal à 25% de votre facture mensuelle. Vous n’avez pas besoin de nous contacter à ce sujet, cela se fera automatiquement sur une de vos prochaines factures. Veuillez noter que ce remboursement peut prendre jusqu’à 90 jours pour être effectif.
Si vous avez une question, n’hésitez pas à nous contacter. Notre service clientèle est disponible 24 heures sur 24 par téléphone ou via une demande (Service Request) depuis le site Microsoft Online Services Administration Center.
Nous vous remercions d’avoir choisi Microsoft Online Services pour héberger vos applications d’entreprise.
Chez Amazon, le problème n'a pas provoqué l'arrêt des services mais a généré la corruption des "instantanés" utilisés comme sauvegarde (alors même qu'ils sont répliqués sur d'autres régions...). Amazon a néanmoins pu reconstruire ces instantanées mais une opération d'administration est nécessaire pour les faire fonctionner. Voici la communication que nous avons reçu suite à l'incident:
Hello,
We've discovered an error in the Amazon EBS software that cleans up unused snapshots. This has affected at least one of your snapshots in the EU-West Region.
During a recent run of this EBS software in the EU-West Region, one or more blocks in a number of EBS snapshots were incorrectly deleted. The root cause was a software error that caused the snapshot references to a subset of blocks to be missed during the reference counting process. This process compares the blocks scheduled for deletion to the blocks referenced in customer snapshots. As a result of the software error, the EBS snapshot management system in the EU-West Region incorrectly thought some of the blocks were no longer being used and deleted them. We've addressed the error in the EBS snapshot system to prevent it from recurring.
We have now disabled all of your snapshots that contain these missing blocks. You can determine which of your snapshots were affected via the AWS Management Console or the DescribeSnapshots API call. The status for any affected snapshots will be shown as "error."
We have created copies of your affected snapshots where we've replaced the missing blocks with empty blocks. You can create a new volume from these snapshot copies and run a recovery tool on it (e.g. a file system recovery tool like fsck); in some cases this may restore normal volume operation. These snapshots can be identified via the snapshot Description field which you can see on the AWS Management Console or via the DescribeSnapshots API call. The Description field contains "Recovery Snapshot snap-xxxx" where snap-xxx is the id of the affected snapshot. Alternately, if you have any older or more recent snapshots that were unaffected, you will be able to create a volume from those snapshots without error. For additional questions, you may open a case in our Support Center: https://aws.amazon.com/support/createCase
We apologize for any potential impact this might have on your applications.

/image%2F1528223%2F20220121%2Fob_0bac06_llaske-2022-carre.png)


/image%2F1528223%2F20190729%2Fob_384a00_computer-1574533-960-720.jpg)
/http%3A%2F%2Fwww.genymotion.com%2Fwp-content%2Fuploads%2F2016%2F11%2Fillu-bugdroid.png)
/http%3A%2F%2Fimages.itnewsinfo.com%2Flmi%2Fimagedujour%2Fgrande%2F000000054675.jpg)
/http%3A%2F%2Fi-cms.journaldunet.com%2Fimage_cms%2F540%2F10412773-jusqu-ici-rivaux-aws-et-vmware-lancent-une-offre-commune-de-cloud-hybride.jpg)